
Every frame has a story.
We read all of them.
Stop tagging videos manually. Mikshi reads visuals, audio, speech, and on-screen text, and gives you answers, not just metadata.
Seamlessly integrated with the platforms powering modern AI
 NVIDIA
NVIDIA Databricks
Databricks Snowflake
Snowflake AWS
AWS Google Cloud
Google Cloud Hugging Face
Hugging Face OpenAI
OpenAI Anthropic
Anthropic MilvusNVIDIADatabricksSnowflakeAWSGoogle CloudHugging FaceOpenAIAnthropicMilvus
MilvusNVIDIADatabricksSnowflakeAWSGoogle CloudHugging FaceOpenAIAnthropicMilvusTwo models. Infinite understanding.
Mikshi ships with two purpose-built video foundation models designed from the ground up for retrieval and reasoning.
Mikshi Analyze 1.0
Reasoning over time
A video-native foundation model that summarizes, explains, and answers questions about anything that happened on screen.
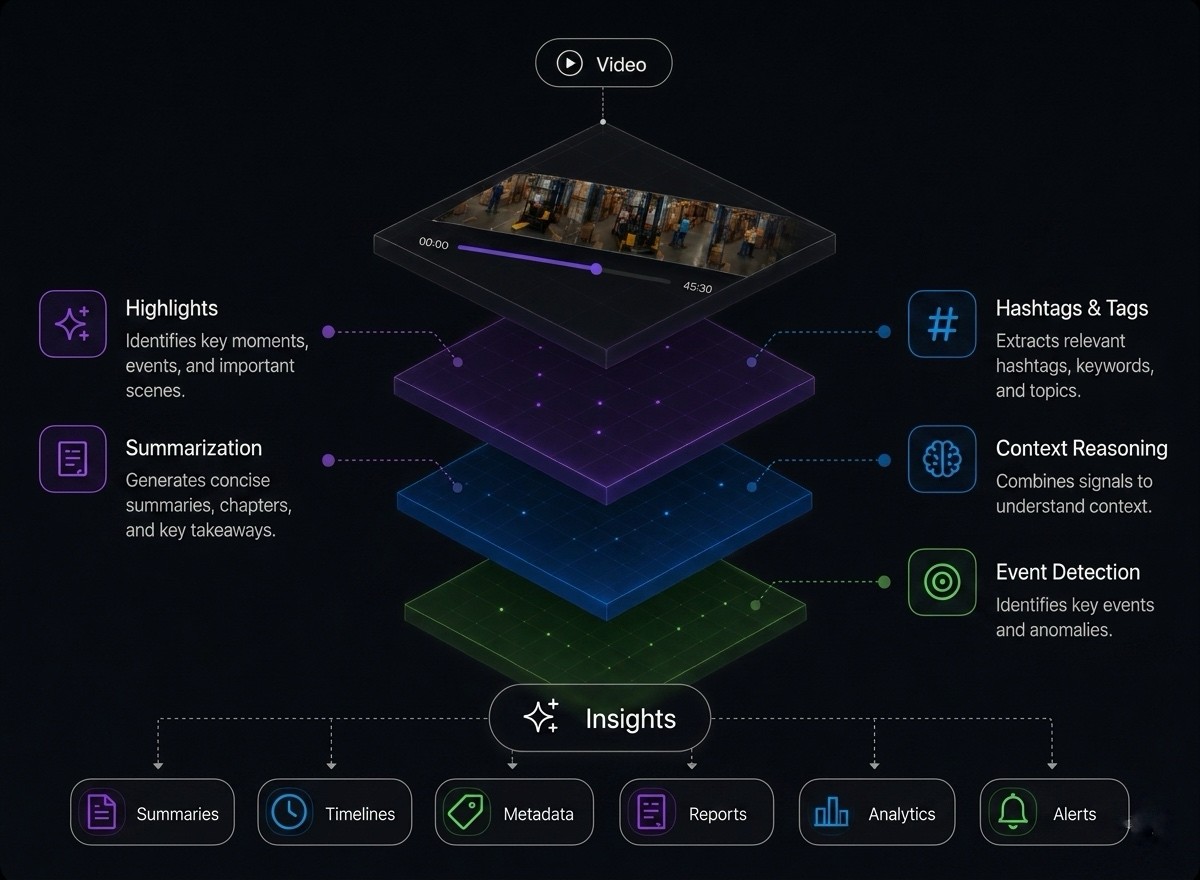
Mikshi Search 1.0
State-of-the-art video embeddings
A unified multimodal embedding space for video, audio, and text. Search any moment using natural language across millions of hours.
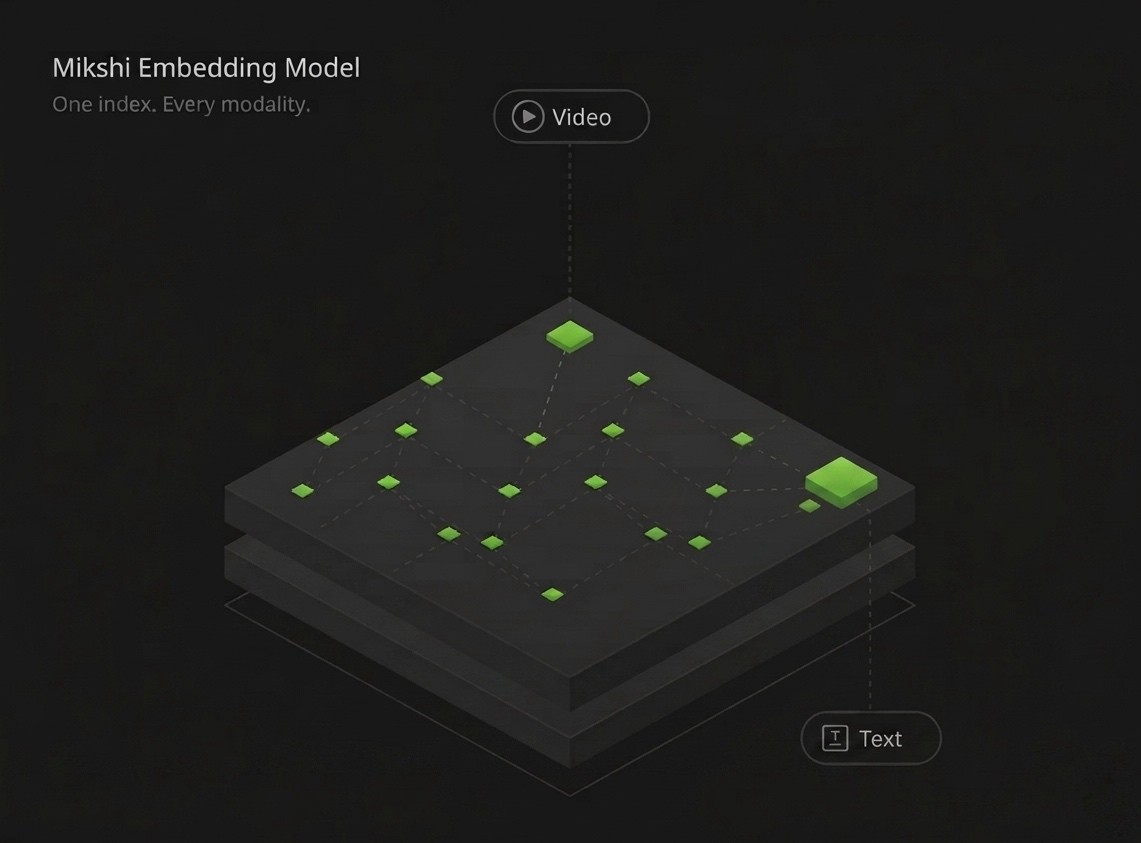
Everything you need to build with video.
One unified API for understanding, retrieval, and generation. Production-ready at scale, with the ergonomics of a great dev tool.
Semantic search
Find any moment in any video using natural language. No tagging, no metadata required.
Video-native chat
Ask questions about hours of footage and get grounded answers with timestamps.
Summarization
Generate chapters, highlights, and abstracts from long-form video automatically.
Auto-tagging
Extract entities, scenes, actions, and brand mentions at frame-level precision.
Anomaly detection
Surface the unexpected, incidents, deviations, and edge cases, in real time.
Embeddings API
Drop high-dimensional video embeddings into your existing vector stack.
Built for every video workflow.
Video intelligence for teams in media, sports, advertising, government, security, and more.
Media & Entertainment
Turn archives from liabilities to strategic assets. Within seconds: timestamped clips, from every year, every shoot. What used to take a research team three days takes three seconds.
Learn moreBuilt for the most demanding video workflows
Designed for organizations working with video at scale, turning raw, passive footage into a strategic asset teams can actually use.
Search entire video libraries using natural language. Locate specific actions, scenes, dialogue, and even human emotions across hours or years of footage, no tags needed. One index. Every modality. SOTA composite accuracy.
From first call to production in minutes.
One SDK. Familiar patterns. Multimodal embeddings, structured generations, and grounded chat, all behind a clean, idiomatic API.
from mikshi import Client client = Client(api_key="msk_...") # Index a video video = client.videos.index( url="s3://my-bucket/keynote.mp4", models=["Mikshi Analyze-1.0", "Mikshi Search 1.0"], ) # Search any moment in natural language hits = client.search.query( index_id=video.index_id, query="the moment the demo crashed", top_k=5, ) for hit in hits: print(hit.start, "→", hit.end, hit.score)
Built for the workflows that video already shapes.
Turn the archive into a search engine
Producers find the perfect clip in seconds, across decades of footage, with no manual logging.
Watch every camera, miss nothing
Continuously monitor thousands of feeds for the events that actually matter, and only those.
Make every meeting a queryable asset
Recordings become a structured, searchable layer of your company's institutional memory.
Start building with Mikshi today.
Free to try. Production-ready in minutes. No credit card required.